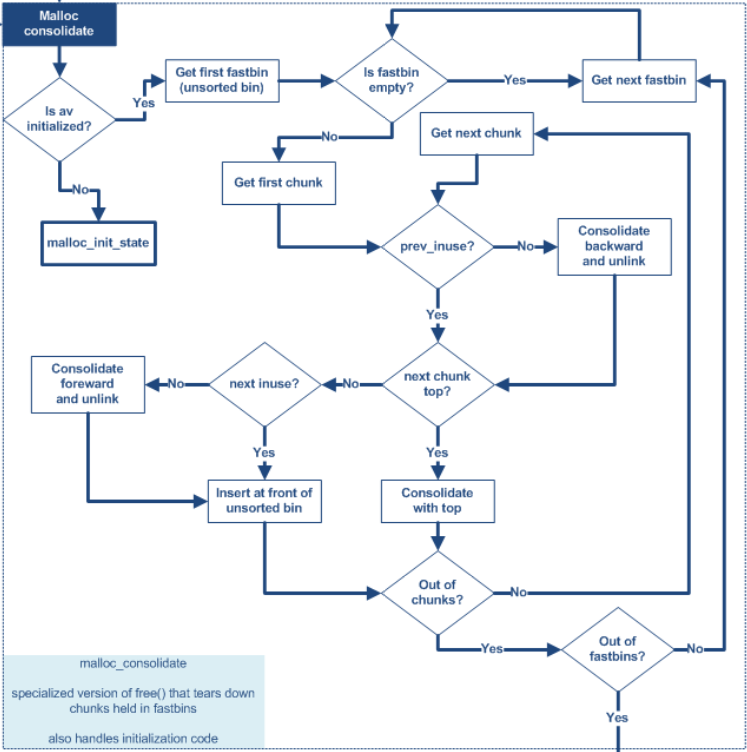
#if __STD_C staticvoidmalloc_consolidate(mstate av) #else staticvoidmalloc_consolidate(av) mstate av; #endif { mfastbinptr* fb; /* current fastbin being consolidated */ mfastbinptr* maxfb; /* last fastbin (for loop control) */ mchunkptr p; /* current chunk being consolidated */ mchunkptr nextp; /* next chunk to consolidate */ mchunkptr unsorted_bin; /* bin header */ mchunkptr first_unsorted; /* chunk to link to */
/* These have same use as in free() */ mchunkptr nextchunk; INTERNAL_SIZE_T size; INTERNAL_SIZE_T nextsize; INTERNAL_SIZE_T prevsize; int nextinuse; mchunkptr bck; mchunkptr fwd;
/* If max_fast is 0, we know that av hasn't yet been initialized, in which case do so below */
if (get_max_fast () != 0) { // 首先判断分配区是否初始化,如果没有就调到最后初始化分配区 clear_fastchunks(av);
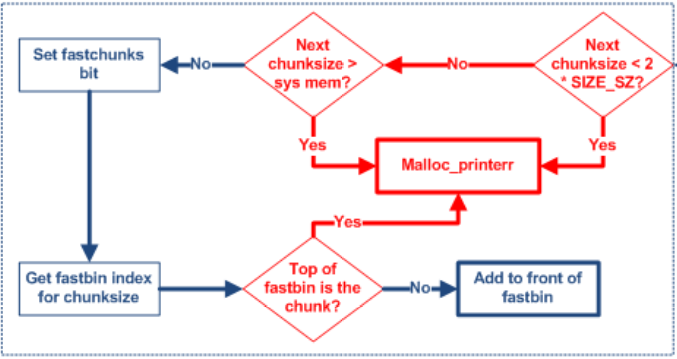
/* Remove each chunk from fast bin and consolidate it, placing it then in unsorted bin. Among other reasons for doing this, placing in unsorted bin avoids needing to calculate actual bins until malloc is sure that chunks aren't immediately going to be reused anyway. */
#if 0 /* It is wrong to limit the fast bins to search using get_max_fast because, except for the main arena, all the others might have blocks in the high fast bins. It's not worth it anyway, just search all bins all the time. */ maxfb = &fastbin (av, fastbin_index(get_max_fast ())); #else maxfb = &fastbin (av, NFASTBINS - 1); // 获取最大的 fastbin 链表 #endif fb = &fastbin (av, 0); // 取出第一条链表 do { #ifdef ATOMIC_FASTBINS p = atomic_exchange_acq (fb, 0); #else p = *fb; // 取出链表的第一个堆块 #endif if (p != 0) { // 判断表是否为空 #ifndef ATOMIC_FASTBINS *fb = 0; #endif do { // 遍历链表 check_inuse_chunk(av, p); nextp = p->fd;
/* Slightly streamlined version of consolidation code in free() */ size = p->size & ~(PREV_INUSE|NON_MAIN_ARENA); nextchunk = chunk_at_offset(p, size); nextsize = chunksize(nextchunk);
if (!prev_inuse(p)) { // 判断是否可以后向合并 prevsize = p->prev_size; size += prevsize; p = chunk_at_offset(p, -((long) prevsize)); unlink(p, bck, fwd); }
if (nextchunk != av->top) { // 判断当前堆块物理上的下一个堆块是否是 top chunk nextinuse = inuse_bit_at_offset(nextchunk, nextsize);
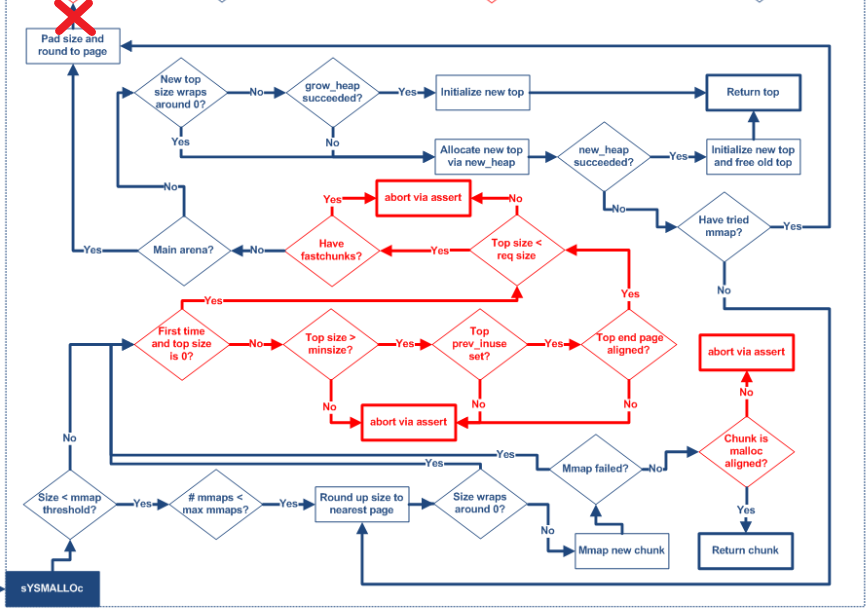
#if __STD_C static Void_t* sYSMALLOc(INTERNAL_SIZE_T nb, mstate av) #else static Void_t* sYSMALLOc(nb, av) INTERNAL_SIZE_T nb; mstate av; #endif { mchunkptr old_top; /* incoming value of av->top */ INTERNAL_SIZE_T old_size; /* its size */ char* old_end; /* its end address */
long size; /* arg to first MORECORE or mmap call */ char* brk; /* return value from MORECORE */
long correction; /* arg to 2nd MORECORE call */ char* snd_brk; /* 2nd return val */
INTERNAL_SIZE_T front_misalign; /* unusable bytes at front of new space */ INTERNAL_SIZE_T end_misalign; /* partial page left at end of new space */ char* aligned_brk; /* aligned offset into brk */
mchunkptr p; /* the allocated/returned chunk */ mchunkptr remainder; /* remainder from allocation */ unsignedlong remainder_size; /* its size */
try_mmap: /* Round up size to nearest page. For mmapped chunks, the overhead is one SIZE_SZ unit larger than for normal chunks, because there is no following chunk whose prev_size field could be used. */ #if 1 /* See the front_misalign handling below, for glibc there is no need for further alignments. */ size = (nb + SIZE_SZ + pagemask) & ~pagemask; #else size = (nb + SIZE_SZ + MALLOC_ALIGN_MASK + pagemask) & ~pagemask; #endif
接着判断一下 HAVE_MMAP 宏定义是否为 1,引用 malloc.c 的注释如下
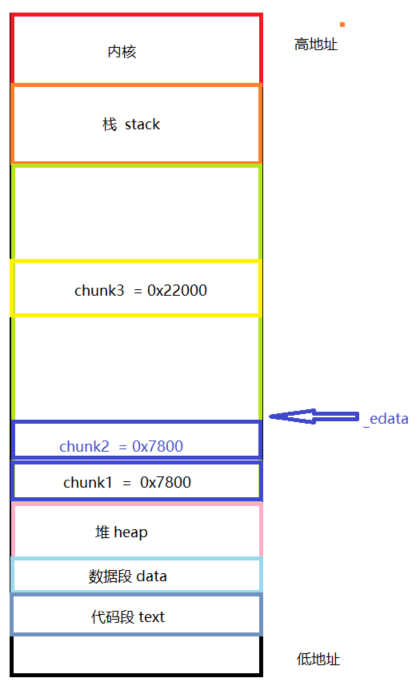
1 2 3 4 5 6 7 8 9
Define HAVE_MMAP as true to optionally make malloc() use mmap() to allocate very large blocks. These will be returned to the operating system immediately after a free(). Also, if mmap is available, it is used as a backup strategy in cases where MORECORE fails to provide space from system.
This malloc is best tuned to work with mmap for large requests. If you do not have mmap, operations involving very large chunks (1MB or so) may be slower than you'd like.
Round up size to nearest page. For mmapped chunks, the overhead is one SIZE_SZ unit larger than for normal chunks, because there is no following chunk whose prev_size field could be used.
/* Don't try if size wraps around 0 */ if ((unsignedlong)(size) > (unsignedlong)(nb)) {
mm = (char*)(MMAP(0, size, PROT_READ|PROT_WRITE, MAP_PRIVATE));
if (mm != MAP_FAILED) {
/* The offset to the start of the mmapped region is stored in the prev_size field of the chunk. This allows us to adjust returned start address to meet alignment requirements here and in memalign(), and still be able to compute proper address argument for later munmap in free() and realloc(). */
#if 1 /* For glibc, chunk2mem increases the address by 2*SIZE_SZ and MALLOC_ALIGN_MASK is 2*SIZE_SZ-1. Each mmap'ed area is page aligned and therefore definitely MALLOC_ALIGN_MASK-aligned. */ assert (((INTERNAL_SIZE_T)chunk2mem(mm) & MALLOC_ALIGN_MASK) == 0); #else front_misalign = (INTERNAL_SIZE_T)chunk2mem(mm) & MALLOC_ALIGN_MASK; if (front_misalign > 0) { correction = MALLOC_ALIGNMENT - front_misalign; p = (mchunkptr)(mm + correction); p->prev_size = correction; set_head(p, (size - correction) |IS_MMAPPED); } else #endif { p = (mchunkptr)mm; set_head(p, size|IS_MMAPPED); }
/* update statistics */
if (++mp_.n_mmaps > mp_.max_n_mmaps) mp_.max_n_mmaps = mp_.n_mmaps;
sum = mp_.mmapped_mem += size; if (sum > (unsignedlong)(mp_.max_mmapped_mem)) mp_.max_mmapped_mem = sum; #ifdef NO_THREADS sum += av->system_mem; if (sum > (unsignedlong)(mp_.max_total_mem)) mp_.max_total_mem = sum; #endif
/* Precondition: not enough current space to satisfy nb request */ assert((unsignedlong)(old_size) < (unsignedlong)(nb + MINSIZE)); #ifndef ATOMIC_FASTBINS /* Precondition: all fastbins are consolidated */ assert(!have_fastchunks(av)); #endif
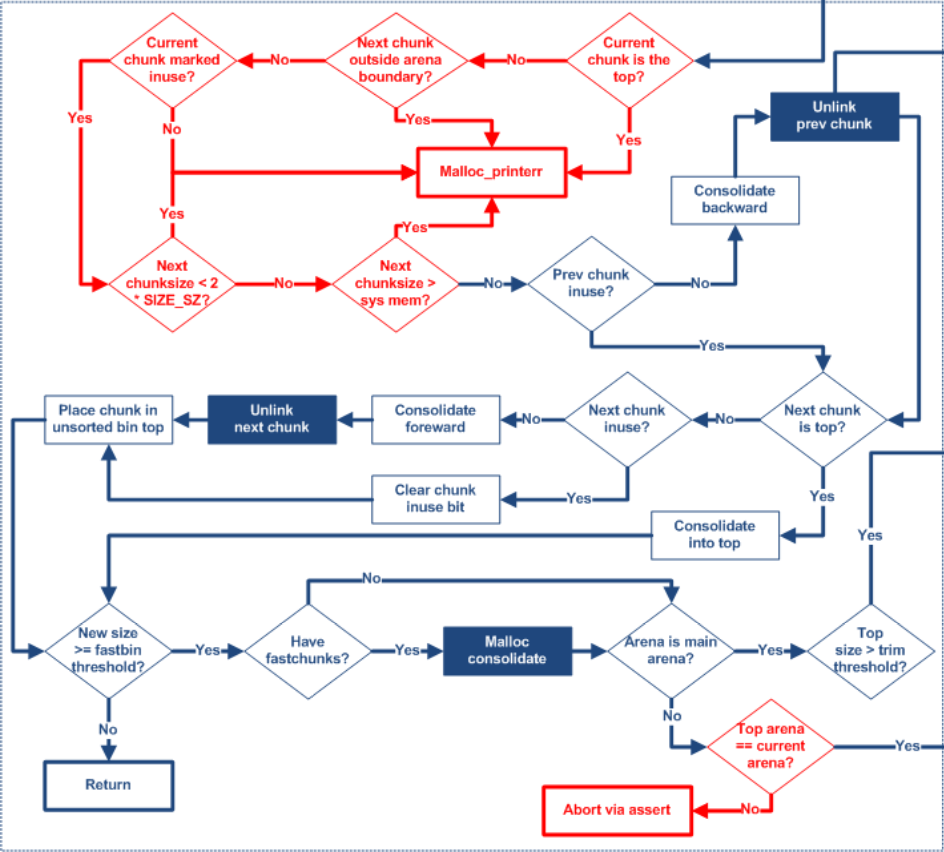
首先保存旧的 top chunk 信息,然后判断 top chunk 是否合法,当程序执行到这里,top chunk 有两种情况,一是没有被初始化,size 等于 0,二是已经被初始化,但是 size 不能满足 nb,这使就要求 size 大于 MINSIZE ,并且 prev_inuse 标志位为 1,并且 top chunk 的尾部是对齐的。
/* Setup fencepost and free the old top chunk. */ /* The fencepost takes at least MINSIZE bytes, because it might become the top chunk again later. Note that a footer is set up, too, although the chunk is marked in use. */ old_size -= MINSIZE; set_head(chunk_at_offset(old_top, old_size + 2*SIZE_SZ), 0|PREV_INUSE); if (old_size >= MINSIZE) { set_head(chunk_at_offset(old_top, old_size), (2*SIZE_SZ)|PREV_INUSE); set_foot(chunk_at_offset(old_top, old_size), (2*SIZE_SZ)); set_head(old_top, old_size|PREV_INUSE|NON_MAIN_ARENA); #ifdef ATOMIC_FASTBINS _int_free(av, old_top, 1); #else _int_free(av, old_top); #endif } else { set_head(old_top, (old_size + 2*SIZE_SZ)|PREV_INUSE); set_foot(old_top, (old_size + 2*SIZE_SZ)); } } elseif (!tried_mmap) // 检查是否还能使用 mmap /* We can at least try to use to mmap memory. */ goto try_mmap;
}
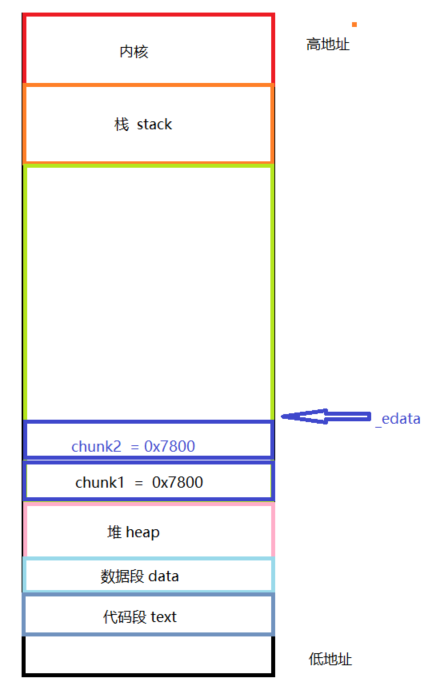
如果当前线程的分配区不是主分配区,会先尝试拓展当前的 heap,通过调整 sub_heap 的边界尝试获取更多的空间,如果失败,就会尝试新建一个 heap(使用 brk() 拓展) ,在新建 heap 的代码中,和 pwn 题有关系的就是 __int_free(av, old_top),这句代码,因为它会将旧的 top chunk 加入到 unsortedbin 中,这也是 house of orange 以及一系列衍生攻击的基础。
/* Little security check which won't hurt performance: the allocator never wrapps around at the end of the address space. Therefore we can exclude some size values which might appear here by accident or by "design" from some intruder. */ if (__builtin_expect ((uintptr_t) p > (uintptr_t) -size, 0) || __builtin_expect (misaligned_chunk (p), 0)) { errstr = "free(): invalid pointer"; errout: #ifdef ATOMIC_FASTBINS if (! have_lock && locked) (void)mutex_unlock(&av->mutex); #endif malloc_printerr (check_action, errstr, chunk2mem(p)); return; } /* We know that each chunk is at least MINSIZE bytes in size. */ if (__builtin_expect (size < MINSIZE, 0)) { errstr = "free(): invalid size"; goto errout; } check_inuse_chunk(av, p);
#ifdef ATOMIC_FASTBINS mchunkptr fd; mchunkptr old = *fb; unsignedint old_idx = ~0u; do { /* Another simple check: make sure the top of the bin is not the record we are going to add (i.e., double free). */ if (__builtin_expect (old == p, 0)) { errstr = "double free or corruption (fasttop)"; goto errout; } if (old != NULL) old_idx = fastbin_index(chunksize(old)); p->fd = fd = old; } while ((old = catomic_compare_and_exchange_val_rel (fb, p, fd)) != fd);
if (fd != NULL && __builtin_expect (old_idx != idx, 0)) { errstr = "invalid fastbin entry (free)"; goto errout; } #else /* Another simple check: make sure the top of the bin is not the record we are going to add (i.e., double free). */ if (__builtin_expect (*fb == p, 0)) // 当前链表的第一个堆块不能是正要插入的堆块,防止 double free 的发生 { errstr = "double free or corruption (fasttop)"; goto errout; } if (*fb != NULL && __builtin_expect (fastbin_index(chunksize(*fb)) != idx, 0)) // 如果当前链表不为空,但是第一个堆块的 size 不符合此链表的大小,说明某处发生了错误 { errstr = "invalid fastbin entry (free)"; goto errout; }
/* Place the chunk in unsorted chunk list. Chunks are not placed into regular bins until after they have been given one chance to be used in malloc. */
/* If freeing a large space, consolidate possibly-surrounding chunks. Then, if the total unused topmost memory exceeds trim threshold, ask malloc_trim to reduce top. Unless max_fast is 0, we don't know if there are fastbins bordering top, so we cannot tell for sure whether threshold has been reached unless fastbins are consolidated. But we don't want to consolidate on each free. As a compromise, consolidation is performed if FASTBIN_CONSOLIDATION_THRESHOLD is reached. */
if ((unsignedlong)(size) >= FASTBIN_CONSOLIDATION_THRESHOLD) { // 如果经过合并的堆块大小超过了 FASTBIN_CONSOLIDATION_THRESHOLD 阈值(64 KB) if (have_fastchunks(av)) // 如果此时 fastbin 链表不为空,就会调用 consolidate 合并 fastbin 中的 chunk malloc_consolidate(av); // 调用 consolidate,将 fastbin chunk 合并到 unsorted bin
if (av == &main_arena) { // 如果当前分配区是主分配区 #ifndef MORECORE_CANNOT_TRIM if ((unsignedlong)(chunksize(av->top)) >= (unsignedlong)(mp_.trim_threshold)) // 如果当前 top chunk 大小大于 heap 的收缩阈值(可以结合上面的 brk 图示理解),就会调用 sYSTRIm 收缩 heap sYSTRIm(mp_.top_pad, av); #endif } else { /* Always try heap_trim(), even if the top chunk is not large, because the corresponding heap might go away. */ heap_info *heap = heap_for_ptr(top(av)); // 如果当前分配区不是主分配区,就调用 heap_trim 收缩 sub_heap
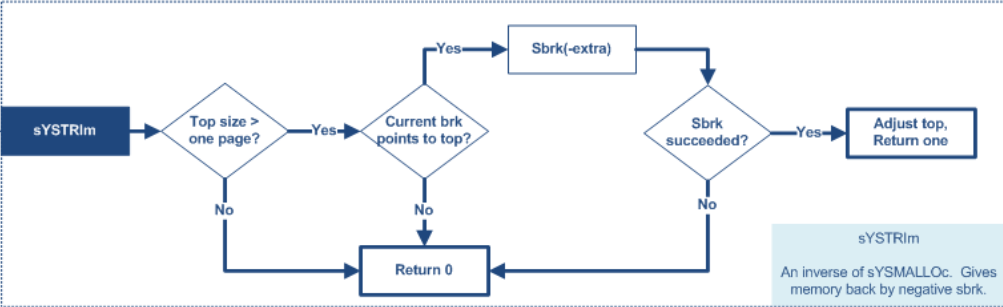
sYSTRIm is an inverse of sorts to sYSMALLOc. It gives memory back to the system (via negative arguments to sbrk) if there is unused memory at the `high' end of the malloc pool. It is called automatically by free() when top space exceeds the trim threshold. It is also called by the public malloc_trim routine. It returns 1 if it actually released any memory, else 0.
/* Release in pagesize units, keeping at least one page */ extra = ((top_size - pad - MINSIZE + (pagesz-1)) / pagesz - 1) * pagesz; // 计算 top chunk 中最大可释放的整数页的数量
if (extra > 0) {
/* Only proceed if end of memory is where we last set it. This avoids problems if there were foreign sbrk calls. */ current_brk = (char*)(MORECORE(0)); // 获取 brk 的值 if (current_brk == (char*)(av->top) + top_size) { // 如果和此时 top chunk 的结束地址相同,说明可以执行 heap 收缩
/* Attempt to release memory. We ignore MORECORE return value, and instead call again to find out where new end of memory is. This avoids problems if first call releases less than we asked, of if failure somehow altered brk value. (We could still encounter problems if it altered brk in some very bad way, but the only thing we can do is adjust anyway, which will cause some downstream failure.) */