De-DeCompiler
简单的花指令。
GCC 简单的内联汇编
GCC 支持在代码中嵌入汇编代码,这些代码被称为“GCC内联汇编”。
内联汇编不只有 GCC 支持,包括微软的 VS 和其他一些编译器也支持内联汇编,GCC的内联汇编语法比较简单,格式如下:
1 | __asm__ [__volatile__] ("指令序列") |
- __asm__ 是 GCC 内联汇编(asm 宏)的关键字,使用它来声明一个内联汇编。
- __volatile__ 是 volatile 的宏定义,它是可选的,用来告诉编译器不要优化或更改下面一段代码。
- 指令序列:主要的汇编指令内容,其基本的编写规则:
1 | 规则1:任意两条指令之间要么被分号(;)或换行符(\n)或(\n\t)分隔开,要么单独放在两行; |
内联汇编还有很多知识点,这里暂时不涉及。
PS: 关于 ASM 宏的源代码可以在这里找到。
反-反编译
最近看雪学院(公众号)发了一篇关于反-反编译的文章(翻译自 Static Analysis of Artefacts Handbook),看完感觉受益匪浅,由于一直以来反编译都是我分析软件必须要使用的,拿来一个软件,首先做的就是拖进 IDA 按下 F5 ,大佬们都说不要依赖 F5 ,因为早晚会碰到F5没法用的时候,看过这篇文章,才真正感觉到这里面的套路之深 ORZ…稍微总结一下学到的东西。
什么是反编译就不用多说了, IDA 的核心功能 F5 就是一个反编译器,它能够将汇编代码转换成伪 C 代码,极大地提高了逆向工作者的工作效率,反编译器还有很多,包括开源的 RETDEC、JEB、Reflector等等。
JAVA 以及 Python 等语言的反编译比较简单,但是 C 和 C++ 等语言反编译起来就比较困难了,这是由语言特性和编译器所决定的,例如几乎无法从 RUST 的反编译结果中提取到有用的信息。
软件的开发者自然不希望自己的劳动成果轻易的就可以被别人分析剽窃,所以针对反编译技术就出现了反-反编译技术。通过反-反编译技术,开发者可以使逆向人员的工作量提升,结合加壳和代码混淆技术,能够软件更加安全(但是一切软件都是可以被破解的,只是时间问题,如果某种保护手段能够使软件在它的生命周期里不被破解,那么这种手段就是成功的)。
简述 IDA 的反编译:目前最常用的反编译器就是Hex-ray decompiler了,所以以它为例,反编译的思想和设计的技术非常复杂,涵盖了很多的知识,但是可以简单的理解一下,IDA 在反编译程序的时候维护了一个虚拟的栈(模拟运行程序?),通过解析程序的逻辑流程(顺序、分支、循环形成 CFG),将汇编代码进行复杂的转化,最后为变量分配名字和寄存器,优化出伪代码,反-反编译就是要针对反编译的流程,找到可以利用的弱点。
实际上,这些额外的垃圾代码通常称为 花指令。
破坏栈帧
由于 IDA 在反编译的时候维护了一个栈,在解析到诸如 PUSH POP 等对栈的大小进行操作的指令时,会模拟这些操作,我们知道,程序在运行过程中,无论调用了哪些函数,函数的栈帧一定是平衡的,即无论栈被抬升多少,在函数返回时,一定会将栈进行恢复。
当 IDA 检测到某一个函数的栈帧不平衡时,就会拒绝反编译这个函数(因为无法确定必要的变量和地址等),并且报出 sp-analysis-fail(栈指针分析失败),相信这个错误我们经常看到,通常就是汇编代码中某处操作了栈(或者 IDA 认为操作了栈)而没有恢复,导致栈帧不平衡。
一些情况下,这是编译器的优化问题,或者是 IDA 自身的解析问题,但是更多的情况下,这是软件的开发者制作的陷阱,比如下面的一个小程序:
1 | // gcc test.c -o test |
编译后使用 IDA 打开,直接在主函数按下 F5 ,得到的代码:
1 | int __cdecl main(int argc, const char **argv, const char **envp) |
可以看到已经非常接近源代码了(不得不说 IDA 的反编译非常强),轻易就可以找到 flag。
但是如果我们在源代码里加入一小段汇编:
1 | // gcc test.c -o test -masm=intel |
在 printf 函数下方加入了一小段汇编代码,这时使用 IDA 打开程序,定位到主函数按下 F5,你会发现IDA报错:
提示栈指针分析失败,那么插入的短短几行代码究竟做了什么,让 IDA 的 F5 失效了?
分析汇编代码不难发现,执行逻辑是先将 RAX 入栈,然后清空 RAX,注意这时 ZF 会被置为 1,然后来到一条跳转(jz),只要 ZF 为 1 则跳转,那么接下来就会跳过 add esp 4 这条指令,将 RAX 恢复然后继续正常流程。
ESP (RSP)是栈顶指针寄存器,它保存了当前的栈顶地址,IDA 在解析执行流时并不知道这里的跳转(jz)是否会得到执行,于是 IDA 会先将所有指令都视为能够执行,ESP就会增加 4 ,但是在代码末尾并没有恢复 ESP 的值,导致了栈帧不平衡, IDA 拒绝反编译这个函数。
分析清楚了原因,那么解决办法很简单,我们将 add esp 4 这条指令 nop 掉,IDA 栈帧就不会被破坏,反编译就可以正常进行。
在继续之前,我们需要明白机器码并不是必须要有严谨的格式或顺序才能被反汇编成汇编代码的,使用 IDA 打开一个程序其中的代码是有逻辑顺序可言的,但是我们也可以打开一个和程序毫不相关的文件,例如一张图片。
我找到一张图片(png),在 IDA 中打开,随意找到一处按下C键,得到了以下代码:
1 | seg000:000000000000004B out 0Ch, eax ; DMA controller, 8237A-5. |
然而这只是一张图片,并不是一个ELF或者EXE的可执行程序,IDA居然可以识别出很多的汇编代码,是不是很惊讶?
事实上,一个二进制文件(图片或视频或音频等等)其中至少有 90% 可以被解析成代码,只是这些代码没有任何意义罢了,那么为什么 IDA 还是会将这些不相关的机器码识别出来?
反汇编器的两种实现方式:
- 线性扫描
- 递归下降
反汇编器所面临了一个难题就是如何区分指令和数据,这在 x86 指令集(x64) 体现的尤其明显,由于指令长度是可变的(字节数不同,可能是为了前向兼容),所以CPU解码的流程异常复杂,导致反汇编工作也非常困难。
关于线性扫描反汇编器,这里借用 PDF 中的解释,一个可执行文件使用十六进制查看,取其中的一小段机器码: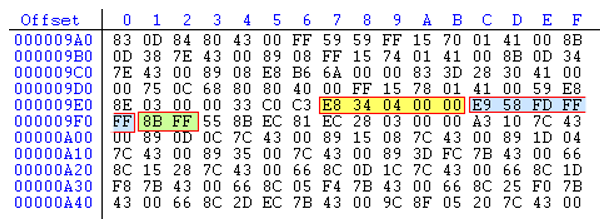
关注其中的高亮部分,指令可以分为三句
- call 0x401a20
- jmp 0x401349
- mov edi,edi
如果将解析指令的起始位置向后移动两个字节,就会得到以下指令序列: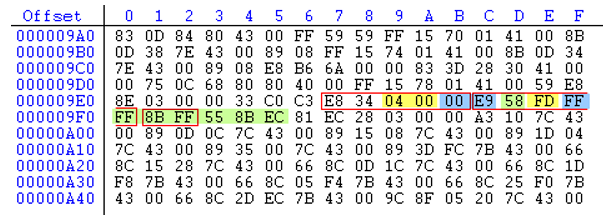
- add al,0x0
- add cl,ch
- pop eax
- std
- db 0xff(error ins)
- dec dword [ebx - 0x1374aa01]
两者进行一下对比,变化非常明显,我们得到的指令完全没有意义,而造成这些后果的原因只是解析指令的开始位置向后移动了两个字节而已。
线性扫描类型的反汇编器会试图解析一个程序代码段的所有机器码,一条指令的开始通常是上一条指令的结尾,并且不会区分指令类型,所以,如果在这些正常的指令之间插入一些垃圾代码(比如一个字符串),就可能会打乱线性扫描反汇编器的整个反汇编流程,导致后续代码全部错误。
例如: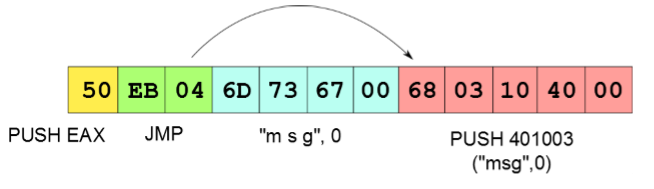
浅蓝色的部分实际上是插入的字符串,它们本不应该被解析成指令,但是线性扫描反汇编器在解析完上一条指令之后,会认为这里也是正常的指令(在代码段),强行解析导致后续的代码都会解析失败(这一类反汇编器的代表:winDBG)。
关于递归下降反汇编器,它和线性扫描型反汇编器最大的区别就是它在解析到某一条更改了控制流的指令时(如 jmp、call、ret等),会尝试获取到跳转的目的地址,并且转向目的地址继续解析代码,而不是直接向后解析。
然而它也不是完美的,在某些情况下,控制流更改的目的地不是确定的,而是动态计算出来(比如 call eax 这样),那么反汇编器也不能确定目的地址,造成的一个后果就是,程序中某些代码一直也没有被调用(或跳转到),那么这部分代码就可能永远也不会被解析(这类反汇编器的代表是 IDA 和 OD)。
接下来继续分析一下反反编译的技术(一些手段在看雪的文章中已经存在详细的分析,这里拿几个稍加分析):
垃圾代码
PDF 中比较简单的一个反反编译策略,也比较有意思。
简单的了解了反汇编器的大致工作原理,我们就可以着手破坏它的工作流程,一个简单的方法就是在正常的代码中夹杂垃圾代码,这些垃圾代码可以是真实的指令,也可以是一些字符串,总之,它们本不应该出现在正常的代码中。
插入的垃圾代码的一般结构可能有以下特征:
1 | jmp lable |
jmp 指令是一定会被执行的,所以内部的 junk code 不会被执行,但是它们还是会对反汇编器造成影响,例如第一种方式提到的破坏 IDA 的栈,使其不平衡。
但是那种方法比较简单,容易被发现,这里会采取一个更加隐秘的方法,将正常的代码插入到垃圾代码中,并更改执行流到垃圾代码。
观察以下代码片段:
1 | push ebp |
有几句代码非常诡异,不像是正常程序应该有的,而且有一条奇怪的指令: call $+5 ,其实它的意思就是调用下一条指令,那么这里发生了什么?
- call $+5,将 call 指令分解,就是 push 下一条指令的地址,然后 jmp 到目的地址继续运行,而这里的目的地址就是下一条指令。
- 运行到 pop eax,将之前压入栈中的地址(就是这条指令的地址)弹出给 eax。
- add eax,10h ,将 eax 中的值加上 0x10。
- call eax,调用经过上面处理的地址。
在 IDA 中可以看到这样的代码: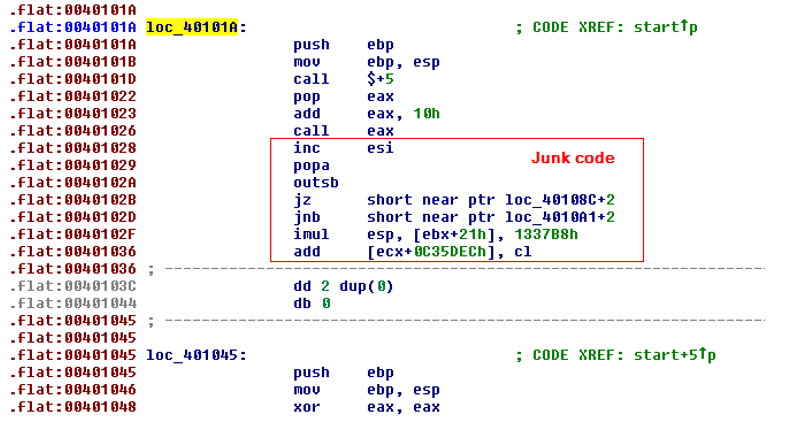
经过计算可以知道,最后的 call eax 实际会执行地址为 0x401032 ,但是目的地址附近的代码并没有在 IDA 中体现出来,其实真实的代码被夹杂在 junk code 中了,在垃圾代码上按下 U 键,然后在正确的地址按下 C 键,就能得出正常代码:
伪造SEH
另一个比较有意思的反反编译方式在 PDF 中给出,那就是伪造一个(或者说是修改现有的)SEH,什么是 SEH?
SEH 全称:结构化异常处理,是 Windows 操作系统上的一种异常处理机制,当程序发生异常时,就会用到这个东西,它是由一些结构体(EXCEPTION_REGISTRATION)串接而成的单向链表,每个结构体内都有两个主要字段:
1 | _EXCEPTION_REGISTRATION struc |
prev 表示下一个结构体的地址,而 handler 就是处理异常的函数。
了解了什么是 SEH ,我们来看一个代码片段: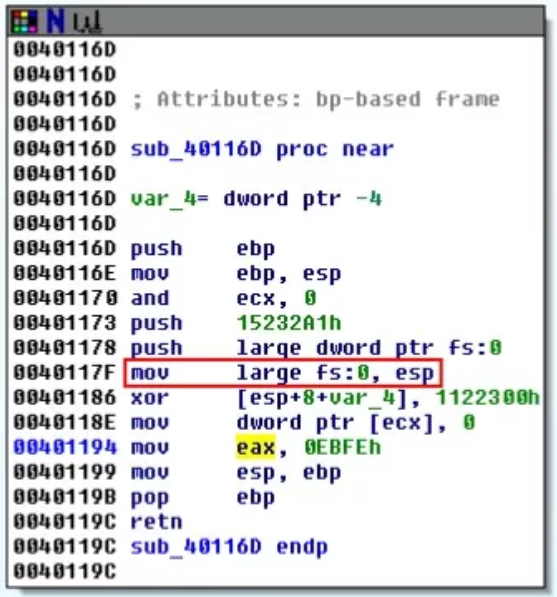
乍一看没有什么异常,但是这里有一条奇怪的指令(图中红框), mov large fs:0,esp ,可以简化为 mov fs[0],esp
将 ESP 即当前栈顶赋值给 fs 段的第一个元素,其实这是一个比较明显的操作:安装 SEH ,这句代码的含义就是把正常的 SEH 链表的第一个结构体的地址迁移到了栈上,即在 ESP 开始的栈空间存在了一个 EXCEPTION_REGISTRATION 结构体,结合代码前面的 push 操作,就可以知道,开发者在栈上制作了一个 EXCEPTION_REGISTRATION 结构,修改了正常的 handler 的值(感觉有些像 PWN OvO),注意在 0x40118E 这句代码,可以转化为 mov dword ptr [0], 0 ,向一个不存在的地址赋值,一定会触发异常,从而调用到了开发者自己制作的 SEH。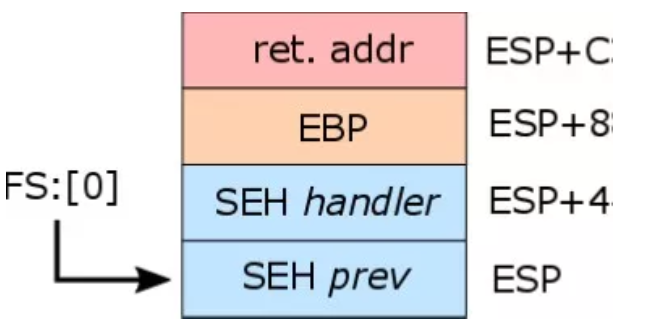
通过计算出这个异常处理函数的地址,我们就能找到真正正确的代码:
总结一下
看了看雪的这篇文章,简单进行小总结,了解到几种很经典的反反编译方法,其中有几个非常巧妙,包括隐藏真实代码到垃圾代码,修改返回地址,注册假的 SEH 等等,反反编译还有更多的方法,虽然手法多种多样,但是最重要的是欺骗反编译器,隐藏程序的实际流程,不过再强的花指令也是可以被清除的,所以通常可以配合软件加壳,代码混淆等技术,增大逆向难度。
识别花指令的办法:当看到某些指令是不常见的,或者一些指令序列毫无逻辑可言,那么就要小心了,因为这里可能就是一段花指令,如果没有明显的花指令出现,那么就要关注特殊的指令序列,包括自行注册 SEH ,修改程序的返回地址等等,其实花指令做到的只是反静态分析,对于经验老到的逆向工作者来说,动态调试通常是破解这些花指令的好办法。
- Title: De-DeCompiler
- Author: Catalpa
- Created at : 2018-11-02 00:00:00
- Updated at : 2024-10-17 08:47:34
- Link: https://wzt.ac.cn/2018/11/02/dedecompiler/
- License: This work is licensed under CC BY-SA 4.0.