PYC 文件的简单分析
最近做 CTF 碰到了有关 pyc 的题目,通常来说这种题目都是用 uncompyle6 直接搞出源代码然后审计,但是某些情况下,反编译 pyc 可能会失败,造成失败的原因有很多,最常见的就是作者将 pyc 中的结构、byte-code或者一些逻辑进行修改和混淆,甚至会修改 python 的源代码来自定义 opcode。今天我们就来简单分析一下 pyc。
PYC 简介
python 语言上手容易,使用简单,并且拥有数量庞大的第三方模块支持,说它目前是最受欢迎的语言之一并不为过,不过任何事物都有两面性,python 也有致命的缺点–运行速度慢。
同时接触过 python 和 C 语言的同学可能很清楚这一点,使用 python 和 C 语言编写两个功能相同的程序,python 程序得出结果可能要花费 2 倍于(甚至更多) C 程序的时间,原因就在于 python 是一种抽象程度更高的语言,并且它使用 python 虚拟机执行代码,而 C 语言更加贴近底层,甚至可以直接和硬件进行交互,谁快谁慢就一目了然了。
python 虚拟机大家可能没有什么概念,但是提到 python byte-code 或者 pyc 文件就不一样了,在开发一个 python 程序的时候,我们经常会看到文件夹下不时出现 *.pyc 这样的文件,将它们全部删除也不会对项目产生什么影响,不过每次运行项目,它们都会重新出现。
实际上, pyc 文件所存储的主体就是 python byte-code 另外还有一些必要的结构。为什么会存在 pyc 文件呢?这就回到了之前的问题上,即 python 运行速度慢,由于计算机无法理解高级语言,我们写的代码必须先被编译成计算机能识别的机器码才能被执行,python 也是一样,不过开发者在机器底层和源代码之间加了一层虚拟机,将许多底层硬件细节进行了封装和屏蔽,使得程序员可以专注于自己的代码逻辑上面,这样也造成了一些弊端,python 程序通常以 .py 为后缀名,其内容就是开发者所编写的源代码,所以,每次运行程序的时候,都需要先编译再执行,当项目代码成千上万行时,如果每次运行都需要编译,那么效率可想而知。
为了解决这个问题。python 的开发者提出了一个很好的解决方案,将一个 python 程序会使用到的模块先编译成 pyc 文件,之后再调用的时候,即可省去编译的时间,提高程序效率。这里的 pyc 文件实际上就是 python 模块的预编译文件。
PYC 格式解析
由于 python 程序的执行依赖于 python 虚拟机,自然有自定义的一套操作码,这些操作码就称为 python 字节码(byte-code)。
pyc 文件中大部分都是字节码,剩下的包括文件头、程序资源、变量符号等等,我们一点一点来看。
首先要生成一个 pyc 文件,例如下面一段很简单的 python 代码
1 | # test1.py |
要想得到 pyc 文件,我们只需要新建另一个文件,然后 import 即可,例如(注意两个文件需要在同一个文件夹下面)
1 | import test1 |
如果不出意外的话,现在文件夹下就会出现一个 test1.pyc 文件。
另外,也可以直接使用 python 命令行的命令
1 | python -m test1.py |
来生成 pyc 文件。
我们可以使用 hexdump(linux 下)来检查这个文件,不过更加明智的方法是利用 010 editor 的模板。
使用 010 editor 打开 pyc 文件,会自动提示是否加载 pyc 模板(如果没有,可以手动在上面的工具栏中运行模板),选择加载,通常你会发现下面的通知栏报出一个错误,大概的意思是没法儿确定 python 版本,这是由于 010 editor 自带的 pyc 模板编写时间比较早,没有兼容后续的 python 版本,我们选择编辑模板,将下面这段代码替换到相应的位置上去。
1 | enum <uint16> MagicValue { |
这样,模板就能正常工作了,我们从模板解析的结果来简单分析一下 pyc 文件结构。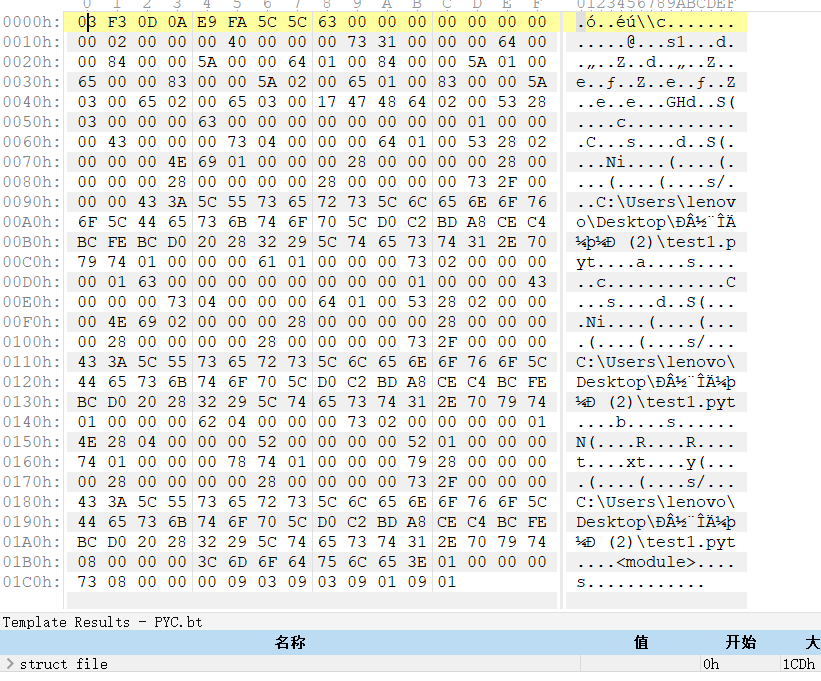
首先点开 struct file,第一项就是 struct Magic magic,这就是所谓的魔数,很多文件都有自己的魔数,例如 java 的魔数 cafebabe 就非常经典。不过 pyc 文件的魔数并没有那么炫酷,它由 4 个字节组成,前两个字节是可变的,它和编译 python 文件的 python 版本有关,接下来两个字节是固定的 0D0A,转换成 ASC 码就是 \r\n,所以如果一个 pyc 文件被以文本形式打开复制到另一个文件中,新文件一般是不会正常工作的,这也是 pyc 的一种简单保护手段。
接下来是 char mtime,它也占据 4 个字节,这个字段表示该 pyc 文件的编译日期,用 unix 时间戳来表示,由于字节的小端序,要反过来看,例如我这里的文件时间戳是 E9FA5C5C,那么转换成真正的时间就是 2019-02-08 11:43:37
然后就是 pyc 文件的主体部分了,010 解析为 struct r_object data,打开之后里面有很多内容,首先是 enum ObjType type(TYPE_CODE),占 1 个字节,用它来表示一个 PyCodeObject 开始了。
PyCodeObject
PyCodeObject 是 pyc 文件的主要组成部分,如果想要了解它的具体生成方法和定义,请阅读 python 源代码中的 Include/code.h 和 Python/marshal.c
一个 PyCodeObject 包含许多小的组成成部分,这些小部分称为 PyObject。
根据 010 模板解析结果,PyObject 第一个字节指明了接下来的内容是什么类型,例如 0x63 就表示后面跟着的是 byte-code,或者 0x28 就表示后面跟着的是常量列表等等,这里有一份定义类型の源代码
1 | //Python/marshal.c:22 |
PyCodeObject 的第一个部分肯定是 TYPE_CODE,表示字节码区块,这也是重点的关注部分,除了 TYPE_CODE,下面的字段如下
1 | argcount 参数个数 |
我们主要关注字节码,字节码类似于机器码,可以通过一定的手段将它们转换成类似于汇编语言的可读代码,这里我们需要用到 python 自带的模块 dis。
编写下面的脚本
1 | import dis |
就可以得到下面的代码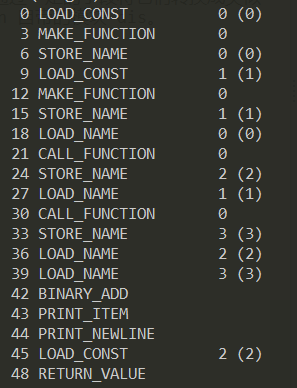
从左到右分为四列,第一列代表字节偏移量,第二列是指令操作码的含义,第三列是操作数,第四列是操作数的说明。
简单分就能得出代码逻辑
1 | 0 LOAD_CONST 0 (0) # 读取常量列表中的 0 号常量 |
这就是简单的字节码分析,要注意我们的程序不包含复杂的代码,如果一个大型程序被编译成了 pyc 文件,就难以分析了。
TYPE_CODE 之后就是其他的 PyObject,例如本例中剩余的有
1 | consts 常量列表 |
这些部分的结构大同小异,就不一一分析了。
这里有一份 PyCodeObject 的具体定义,感兴趣的同学可以仔细看看。
1 | //Include/code.h |
下面要提一下 PyCodeObject 的细节,如果你动手操作可能会发现,一个 pyc 文件里面包含很多的 PyCodeObject,实际上,一个 PyCodeObject 的定义范围是有限的,例如一个函数就定义在一个 PyCodeObject 里面,一个类、闭包等等都分别定义在不同的 PyCodeObject 里。
这张图片可以帮助理解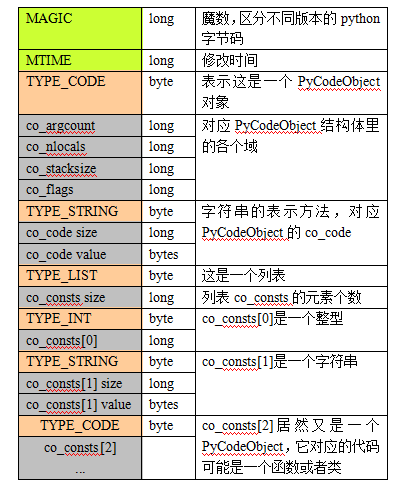
PYC 字节码处理
保护 python 程序难度很高,因为 python 程序的载体 .py 就是源代码文件,虽然有 pyc 这种不能直接看懂的文件,但是由于 uncompyle6 这样的神器存在,解析它也不在话下,目前保护 python 程序的思路一般是对变量名进行混淆,或者操作 pyc 文件混淆字节码,显然后者的效果要更好一些。
python 也好 C 语言也罢,万变不离其宗,python 的字节码处理其实和混淆一个 exe 程序类似,简单的包括跳转混淆、控制流混淆,复杂一些的可能涉及 byte-code 加密等等。
我们拿出最简单的一种方法分析,通过强制跳转干扰反编译器的工作。
首先要了解一些字节码的知识,可以用下面的代码获取你当前版本的 python 字节码表
1 | import opcode |
在 pyc 文件中,字节码的格式一般是 opcode + 操作数,如果想要利用强制跳转实现字节码混淆的话,首先要找到强制跳转的字节码,我的机器上这条指令字节码是 0x71,我们会尝试构造这种结构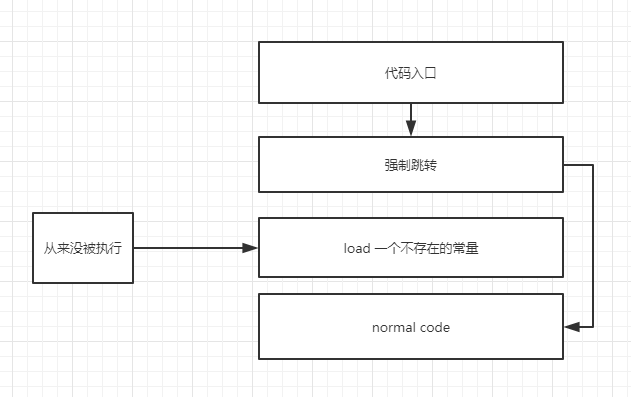
uncompyle 的工作原理和一般的反编译器类似,它会尽力去匹配每一条指令,尝试将所有指令都覆盖到,但是在解析上面的代码时,碰到 load 不存在的常量时就会出错,无法继续反编译。
按照思路将 pyc 修改:
(0x37 是修改的字节,剩下的是添加的字节)修改之后的文件还是能正常运行,使用 python test1.pyc 即可运行。
然后丢到 linux 尝试 uncompyle6 反编译
提示元组越界,这就是反编译到 649000 这句代码时尝试访问非法内存导致的!
类似的操作手法还有很多,具体思路可以参考如何混淆一个 exe 程序。
破釜沉舟: 一个思路是把 python 源代码取下来,将内部的 opcode 部分进行重新排序再编译回 python 解释器,用这种解释器编译的 pyc 代码用一般手段是不能反编译的,这就是 byte-code 加密,案例可以参考《阴阳师:一个非酋的逆向旅程》
总结
pyc 文件格式相较于 pe、elf 等老油条来说还是相当友好的,这得益于 Python的设计哲学 – python之禅
1 | 优美胜于丑陋 |
当然,这种简洁至上的设计思想也决定了 python 不能以效率致胜,不过这也无法阻挡程序员对它的热爱。
Reference
- Title: PYC 文件的简单分析
- Author: Catalpa
- Created at : 2019-02-13 13:00:00
- Updated at : 2024-10-17 08:52:18
- Link: https://wzt.ac.cn/2019/02/13/pyc-simple/
- License: This work is licensed under CC BY-SA 4.0.